

About Me
I'm a second-year MS student at The Ohio State University, focusing on computer vision, machine learning, and multimodal learning (VLMs). Currently, I'm a full-time Computer Vision Engineer Intern at Ubihere, working on multi-camera systems for tracking, re-identification, and spatial analysis. Previously, I did reaserch at PCVLab as a GRA, with Alper Yilmaz, working on computer vision and multimodal learning for medical imaging. We have a dataset paper in revision at Nature Scientific Data, and our dataset has 6K+ downloads on Hugging Face. I like turning research into real systems and experimenting with new tech—recently built a robotics app integrating LLMs and computer vision for the Reachy Mini robot. Looking for full-time AI/ML roles starting May 2026.
Highlighted Skills
Projects
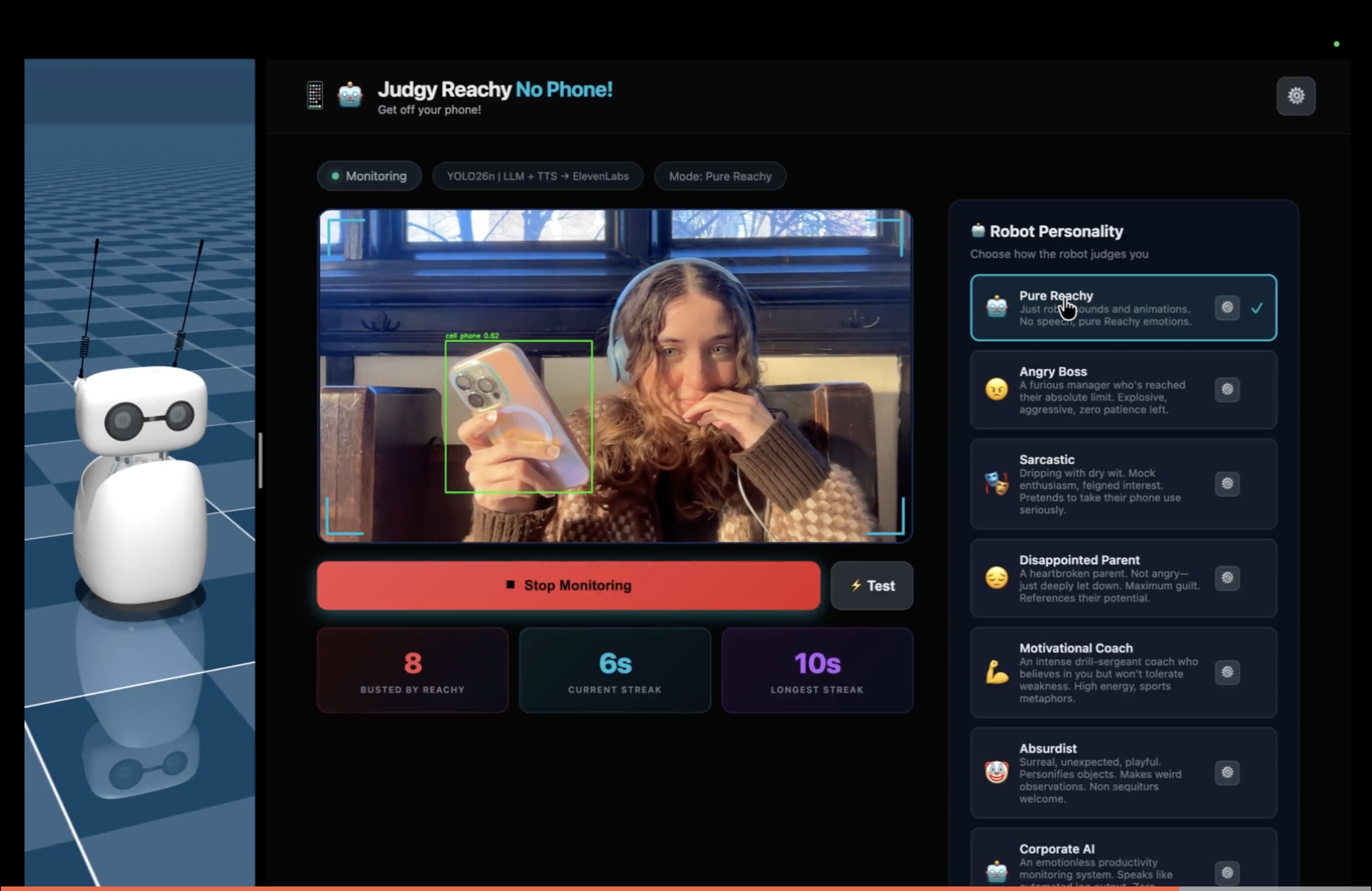
- Built a Reachy Mini robot (Hugging Face x Pollen Robotics) app that detects phone usage in real-time and delivers feedback via robot motion and speech.
- It watches you, catches you scrolling on your phone, and gives you a funny shaming response depending on its mood for your phone addiction :)
- YOLO26 nano — the newest model from Ultralytics (just released!) for real-time phone detection with cross-platform GPU support (CUDA/MPS/CPU).
- Groq API — for Llama 3.1-8b-instant model for LLM that generates 8 unique personalities (plus a 9th “pure Reachy” mode using Pollen Robotics’ pre-written emotions and movements library/dataset)
- ElevenLabs — for giving each personality more realistic voice

Built a real-time object detection system for German supermarket products using YOLOv8m and webcam input. The system is designed to eventually guide users to the correct storage locations based on recognized items in the kitchen.
- Collected and annotated the Freiburg Groceries Dataset and augmented it via Roboflow
- Achieved 87.2% accuracy with YOLOv8m model
- Experimented with a Keras-OCR pipeline I implemented to interpret German-labeled packaging
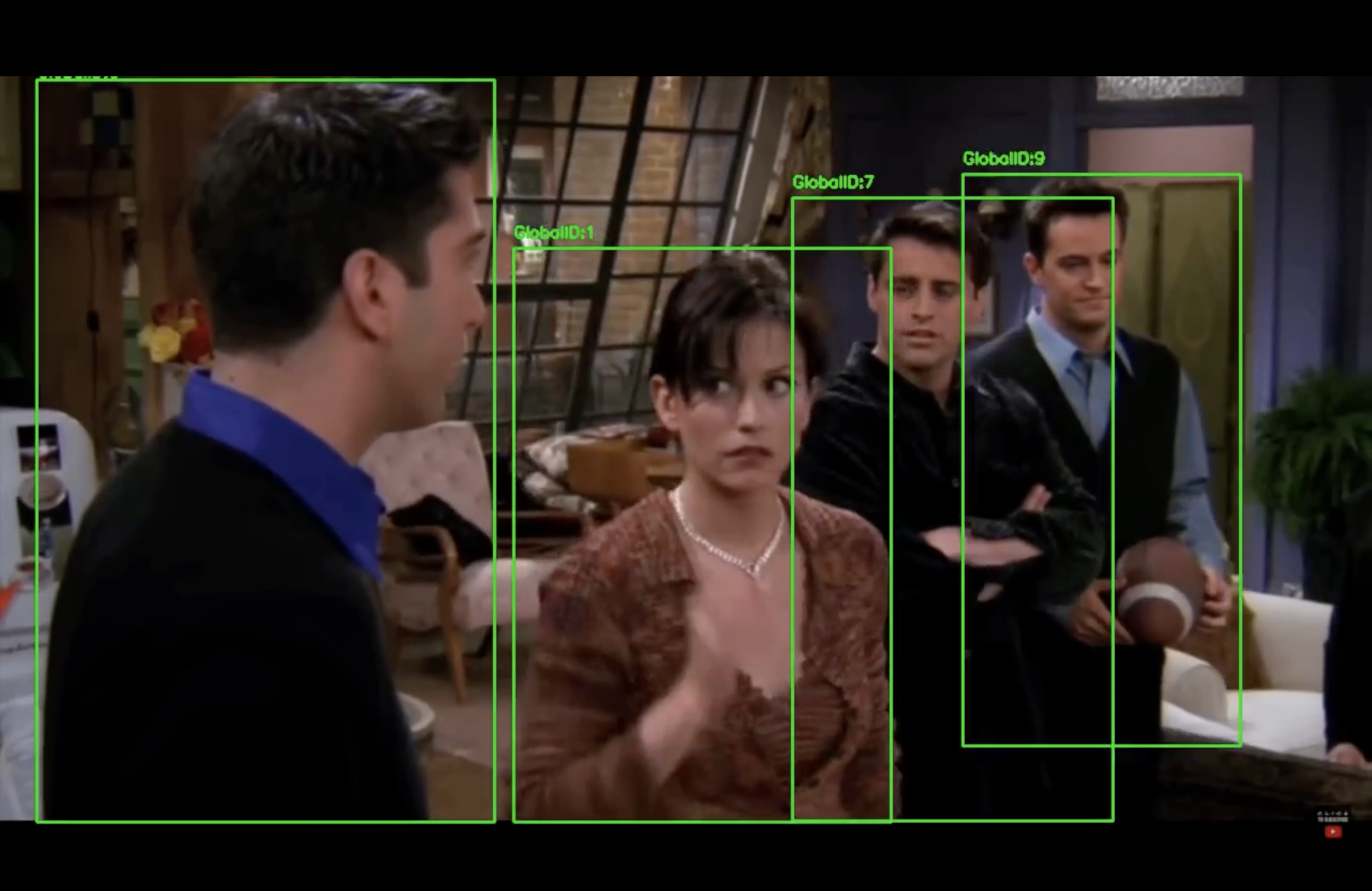
Built a GPU-powered, LangGraph-orchestrated pipeline that detects, tracks, and re-identifies people across a video—then leverages LLM reasoning to link identities.
- Designed a LangGraph workflow to orchestrate detection, cropping, description, and ID matching.
- Integrated a YOLOv8 detector to extract and crop person bounding boxes from each video frame.
- Used Qwen2.5-VL-3B-Instruct to generate rich, structured descriptions (e.g., clothing, hair, accessories) from cropped images.
- Built a persistent memory store of
{global_id, description}entries for identity tracking. - Implemented an LLM agent (Qwen2.5-7B-Instruct) to reason over descriptions and assign global IDs or create new ones.
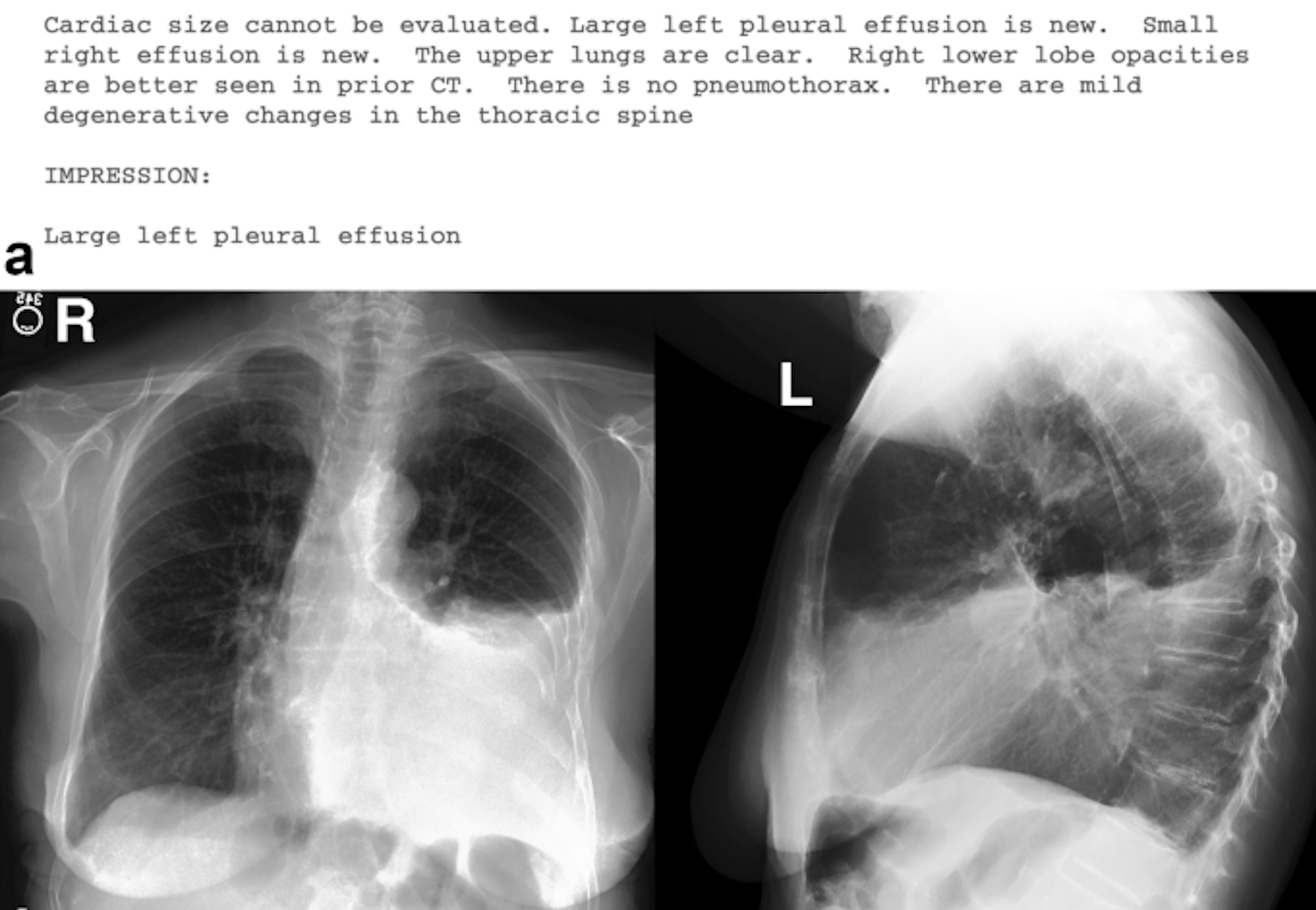
Developing a multimodal vision-language model (VLM) for automatic chest X-ray interpretation and clinical-report generation by learning joint image–text representations from the MIMIC-CXR dataset.
- Curated & pre-processed down to 50 k+ paired studies (frontal + lateral views) from the MIMIC-CXR dataset, along with the findings and impressions.
- Fine-tuning LLaMA 3.2 with Unsloth library, ViT, and GPT variants with masked-patching and multi-view fusion to learn joint embeddings.
- Scaled training across multi-GPU HPC clusters using PyTorch, Hugging Face Accelerate, and SLURM to enable rapid experimentation.
Papers
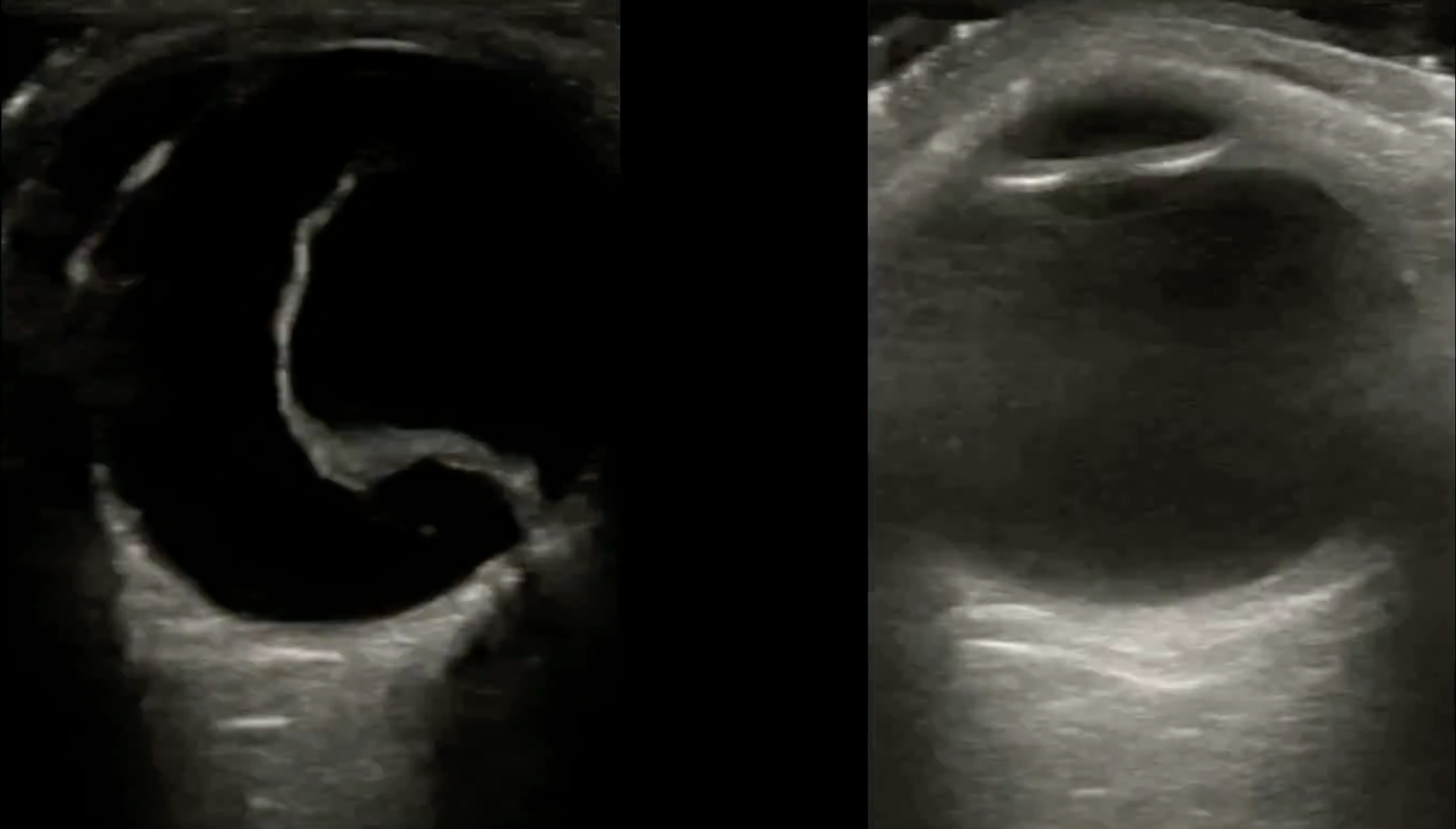
Nature Scientific Data 2025 (Submitted - In revisions)
Project page | arXiv
Contributed extensively to the paper and experimentation phase, collaborating with a colleague who adapted the initial Lightning-Hydra codebase.
- Drafted the Overleaf manuscript and conducted a comprehensive literature review using papers provided by our clinician co-author, Dr. Adhikari.
- Authored the Background and Related Work sections; contributed to writing all remaining sections.
- Developed a Python script to generate stratified train/val/test splits for two binary tasks:
1. Normal vs. Retinal Detachment
2. Macula Detached vs. Intact - Debugged and extended a Lightning-Hydra training pipeline, originally adapted by a colleague from an open-source GitHub template, to support stable distributed training and modular experimentation.
- Trained and evaluated 16 models across 8 architectures with hyperparameter tuning (epochs, learning rate, optimizer, batch size) for both classification tasks, achieving accuracy ranges of:
– 0.937–0.991 (Normal vs. RD)
– 0.725–0.882 (Macula Detached vs. Intact)
Acknowledgement – Pouyan Navard provided the original Lightning-Hydra template, baseline models (ViT, UNETR, SwinUNETR, V-Net, UNet++, SENet154, 3D ResNet, and 3D UNet), dataset, and pipeline.

Contact Me
ozkut1@osu.edu